imagem#
Aprenda a usar o Xinference para gerar imagens.
Introdução#
A API de Images fornece dois métodos para interagir com imagens:
O endpoint de texto para imagem cria imagens a partir do zero com base em texto.
O endpoint de imagem para imagem permite que você gere variações de uma imagem fornecida.
Ponto de extremidade da API |
Endpoint compatível com OpenAI |
|---|---|
Text-to-Image API |
/v1/images/generations |
Image-to-image API |
/v1/images/variations |
Lista de modelos suportados#
Text-to-image API no Xinference suporta os seguintes modelos:
sd-turbo
sdxl-turbo
stable-diffusion-v1.5
stable-diffusion-xl-base-1.0
sd3-medium
sd3.5-medium
sd3.5-large
sd3.5-large-turbo
FLUX.1-schnell
FLUX.1-dev
Kolors
hunyuandit-v1.2
hunyuandit-v1.2-distilled
cogview4
Qwen-Image
Lista de modelos suportados
Flux.1-Kontext-dev
Qwen-Image-Edit
Início Rápido#
Texto para imagem#
Você pode tentar usar a API de Texto para Imagem por meio de cURL, OpenAI Client ou Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/generations' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "<MODEL_UID>",
"prompt": "an apple",
}'
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.generate(
model=<MODEL_UID>,
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
model.text_to_image(input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
imagem para imagem#
A API de imagem para imagem simula a API de criação de variações de imagem do OpenAI. Podemos experimentar a API de imagem para imagem usando cURL, o cliente OpenAI ou o cliente Python do Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/variations' \
-F model=<MODEL_UID> \
-F image=@xxx.jpg \
-F prompt="an apple"
import openai
client = openai.Client(
api_key="cannot be empty",
base_url="http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
client.images.create_variation(
model=<MODEL_UID>,
image=open("image_edit_original.png", "rb"),
prompt="an apple"
)
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>")
input_text = "an apple"
with open("xxx.jpg", "rb") as f:
model.image_to_image(f.read(), input_text)
{
"created": 1697536913,
"data": [
{
"url": "/home/admin/.xinference/image/605d2f545ac74142b8031455af31ee33.jpg",
"b64_json": null
}
]
}
Otimização de memória para modelos de imagem grandes (por exemplo, SD3-Medium, FLUX.1)#
Nota
A partir da v0.16.1, o Xinference ativa por padrão a quantização para modelos de imagem grandes, como as séries Flux.1 e SD3.5. Se você estiver usando uma versão do Xinference mais recente que a v0.16.1, não precisa fazer nada para executar esses modelos de imagem grandes em máquinas com pouca memória de GPU.
Argumentos adicionais úteis passados para carregar o modelo incluem:
--cpu_offload True: QuandoTruefor especificado, os componentes do modelo serão descarregados para a CPU durante a inferência para economizar memória, o que resultará em um leve aumento na latência da inferência. O descarregamento do modelo move os componentes para a GPU apenas quando necessário para execução, mantendo os demais componentes na CPU.--quantize_text_encoder <text encoder layer>:Utilizamos a bibliotecabitsandbytespara carregar e quantizar o codificador de texto T5-XXL em precisão de 8 bits. Isso permite que você continue usando todo o codificador de texto com um impacto mínimo no desempenho.--text_encoder_3 None: para o sd3-medium, remover o T5-XXL, que possui 4,7 bilhões de parâmetros e é intensivo em memória durante a inferência, pode reduzir significativamente os requisitos de memória, com apenas uma leve perda de desempenho.`--transformer_nf4 True`: Usar quantização nf4 no transformer.--quantize: aplicável apenas ao mecanismo MLX no Mac. Flux.1-dev e Flux.1-schnell utilizam o mecanismo MLX para computação no Mac, equantizepode ser usado para quantizar o modelo.
Para WebUI, basta adicionar parâmetros extras, como adicionar a chave cpu_offload e o valor True para ativar o descarregamento da CPU.
Abaixo estão listados os parâmetros usados por padrão a partir da v0.16.1.
model |
quantize_text_encoder |
quantize |
transformer_nf4 |
|---|---|---|---|
FLUX.1-dev |
text_encoder_2 |
True |
False |
FLUX.1-schnell |
text_encoder_2 |
True |
False |
sd3-medium |
text_encoder_3 |
N/A |
False |
sd3.5-medium |
text_encoder_3 |
N/A |
False |
sd3.5-large |
text_encoder_3 |
N/A |
True |
sd3.5-large-turbo |
text_encoder_3 |
N/A |
True |
Qwen-Image |
text_encoder |
N/A |
False |
Qwen-Image-Edit |
text_encoder |
N/A |
False |
Nota
Se você quiser desativar alguma quantização, basta definir a opção correspondente como False. Por exemplo, para a interface Web, defina a chave quantize_text_encoder e o valor False, ou, para a linha de comando, especifique --quantize_text_encoder False para desativar a quantização do codificador de texto.
Para o CogView4, descobrimos que a quantização impacta significativamente o modelo. Portanto, quando a memória da GPU é limitada, recomendamos ativar a opção de CPU offload na Web UI ou especificar --cpu_offload True ao carregar o modelo pela linha de comando.
Formato de arquivo GGUF#
O formato de arquivo GGUF oferece opções de quantização avançadas para o módulo Transformer. Para usar um arquivo GGUF, você pode especificar a opção adicional gguf_quantization na interface web, ou --gguf_quantization na linha de comando, a fim de habilitar a quantização GGUF para modelos com suporte nativo no Xinference. A seguir estão os modelos com suporte integrado.
model |
Suporta o formato de quantização GGUF |
|
|---|---|---|
FLUX.1-dev |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
FLUX.1-schnell |
F16, Q2_K, Q3_K_S, Q4_0, Q4_1, Q4_K_S, Q5_0, Q5_1, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-medium |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
sd3.5-large |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
sd3.5-large-turbo |
F16, Q4_0, Q4_1, Q5_0, Q5_1, Q8_0 |
|
Qwen-Image |
F16, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Qwen-Image-Edit-2509 |
Q2_K, Q3_K_M, Q3_K_S, Q4_0, Q4_1, Q4_K_M, Q4_K_S, Q5_0, Q5_1, Q5_K_M, Q5_K_S, Q6_K, Q8_0 |
|
Nota
Recomendamos fortemente ativar a opção adicional cpu_offload na interface WebUI e defini-la como True, ou, na linha de comando, especificar --cpu_offload True.
Por exemplo:
xinference launch --model-name FLUX.1-dev --model-type image --gguf_quantization Q2_K --cpu_offload True
Usando a quantização Q2_K, você só precisa de aproximadamente 5 GB de VRAM para executar o Flux.1-dev.
Para modelos que não possuem suporte nativo à quantização GGUF, ou se você deseja baixar manualmente o arquivo GGUF, você pode especificar a opção adicional gguf_model_path na interface web ou usar o comando --gguf_model_path /caminho/para/modelo_quant.gguf na linha de comando.
Lightning LORA suporta#
O Lightning LORA destila o modelo na forma de LoRA, mantendo o desempenho do modelo enquanto reduz o número de etapas de inferência e aumenta significativamente a velocidade de inferência. Os seguintes modelos atualmente suportam esta LoRA:
model |
Versões do Lightning compatíveis |
|
|---|---|---|
Qwen-Image |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0, 8steps-V1.1-bf16, 8steps-V1.1 |
|
Qwen-Image-Edit |
4steps-V1.0-bf16, 4steps-V1.0, 8steps-V1.0-bf16, 8steps-V1.0 |
|
Qwen-Image-Edit-2509 |
4steps-V1.0-bf16, 4steps-V1.0-fp32, 8steps-V1.0-bf16, 8steps-V1.0-fp32 |
|
4 passos ou 8 passos referem-se ao número de passos de inferência (num_inference_steps). Quando lightning_version é especificado, o Xinference define automaticamente os passos de inferência.
Ao usar, você pode selecionar a versão lightning na interface ou especificá-la via linha de comando.
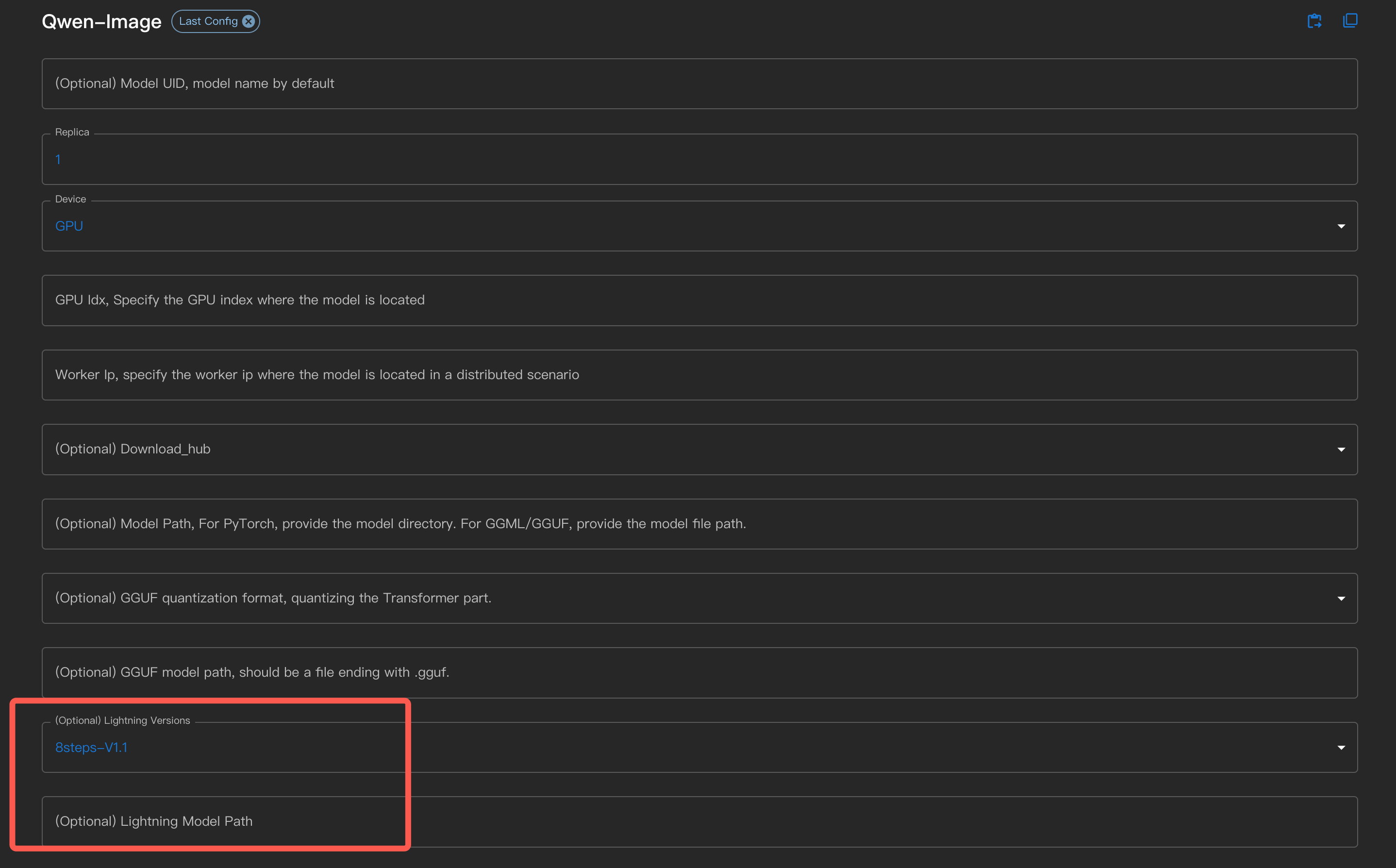
Na linha de comando, use --lightning_version <version>.
Para usuários que baixaram o arquivo LoRA lightning por conta própria, podem especificá-lo na interface através do Lightning Model Path, ou usar o parâmetro de linha de comando --lightning_model_path.
Por exemplo, ao usar 4steps-V1.0, o tempo de inferência foi reduzido de 34 segundos para 3 segundos.
OCR#
A API OCR aceita bytes de imagem e retorna o texto OCR.
Você pode testar a API de OCR usando cURL ou o cliente Python do Xinference.
curl -X 'POST' \
'http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1/images/ocr' \
-F model=<MODEL_UID> \
-F 'kwargs={"model_size":"large"}' \
-F image=@xxx.jpg
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model("<MODEL_UID>", model_size="large")
with open("xxx.jpg", "rb") as f:
model.ocr(f.read())
<OCR result string>