Multimodal#
Aprenda a usar LLMs para processar imagens e áudio.
Visual#
Com a capacidade vision, você pode fazer com que o modelo receba imagens e responda a perguntas sobre elas. No Xinference, isso significa que certos modelos conseguem processar entradas de imagem durante conversas via Chat API.
Lista de modelos suportados#
No seguinte, os modelos suportados com funcionalidade vision no Xinference são:
qwen-vl-chat
deepseek-vl-chat
omnilmm
cogvlm2
MiniCPM-Llama3-V 2.5
glm-edge-v
Início Rápido#
O modelo pode obter imagens de duas maneiras principais: passando um link da imagem ou transmitindo diretamente a imagem codificada em base64 na requisição.
Exemplo de uso do cliente OpenAI#
import openai
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": "http://i.epochtimes.com/assets/uploads/2020/07/shutterstock_675595789-600x400.jpg",
},
},
],
}
],
)
print(response.choices[0])
Envie a imagem codificada em Base64.#
import openai
import base64
# Function to encode the image
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Path to your image
image_path = "path_to_your_image.jpg"
# Getting the base64 string
b64_img = encode_image(image_path)
client = openai.Client(
api_key="cannot be empty",
base_url=f"http://<XINFERENCE_HOST>:<XINFERENCE_PORT>/v1"
)
response = client.chat.completions.create(
model="<MODEL_UID>",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "What’s in this image?"},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{b64_img}",
},
},
],
}
],
)
print(response.choices[0])
Limitar o número de imagens em cada rodada de diálogo.#
Para modelos visuais que utilizam o backend VLLM, você pode limitar a quantidade de imagens processadas por rodada de diálogo através do parâmetro limit_mm_per_prompt. Isso ajuda a controlar o uso de memória e melhorar o desempenho.
# Launch model with image count limitation using Python client
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
# Launch model and set maximum 4 images per conversation turn
model_uid = client.launch_model(
model_name="qwen2.5-vl-instruct",
model_engine="vLLM",
model_format="pytorch",
quantization="none",
model_size_in_billions=3,
limit_mm_per_prompt="{\"image\": 4}"
)
Ou, você pode iniciar o modelo pela linha de comando:
# Launch model with image count limitation using CLI
xinference launch \
--model-engine vLLM \
--model-name qwen2.5-vl-instruct \
--size-in-billions 3 \
--model-format pytorch \
--quantization none \
--limit_mm_per_prompt "{\"image\":4}"
Para a interface web, você pode definir o parâmetro limit_mm_per_prompt no formulário do mecanismo vLLM:
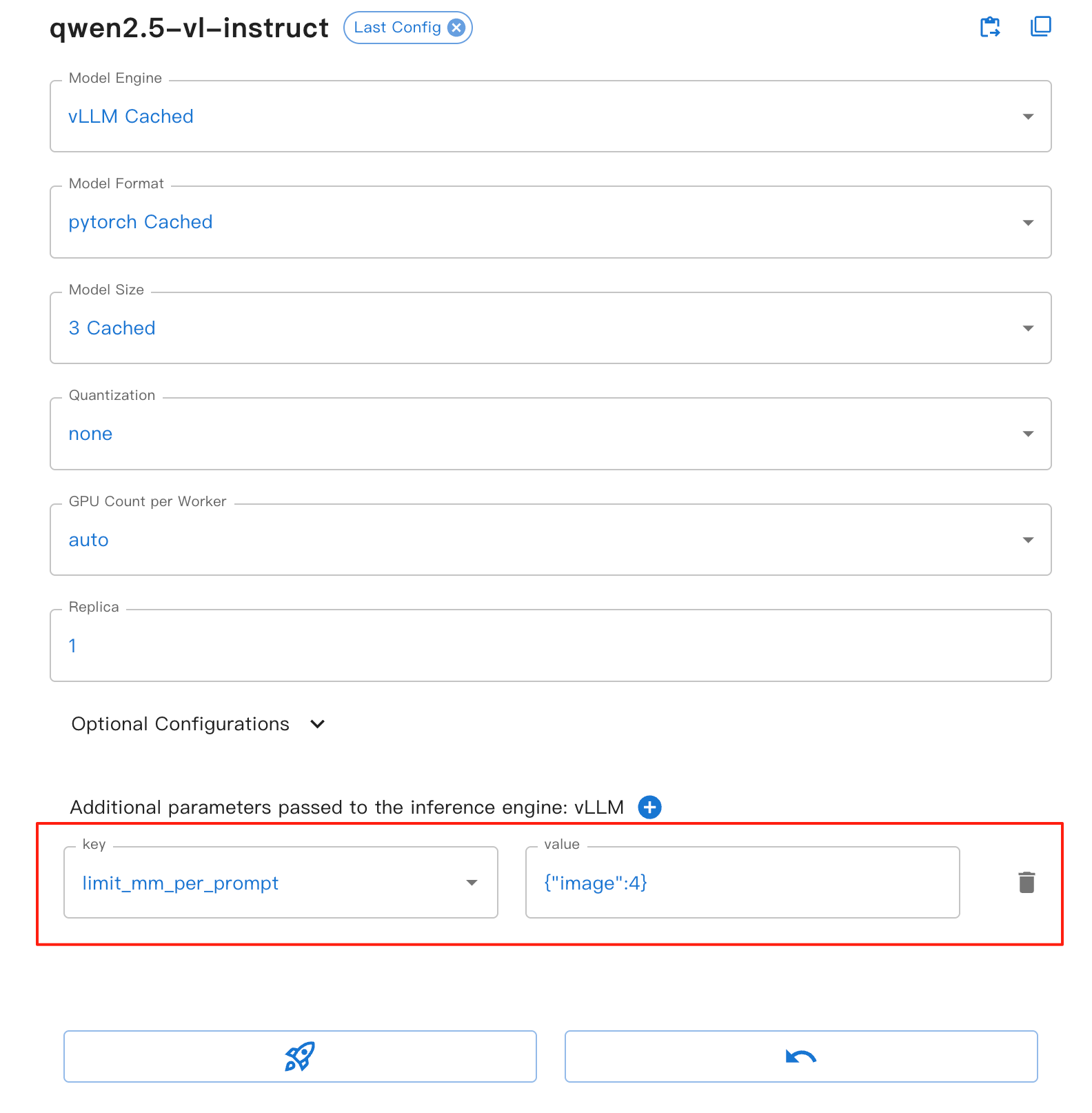
Este parâmetro oferece os seguintes benefícios:
image: Define o número máximo de imagens permitidas por rodada de diálogo.
Ajuda a evitar estouro de memória, especialmente ao processar várias imagens.
Melhore a estabilidade e o desempenho da inferência do modelo.
Aplicável a todos os modelos visuais baseados em VLLM.
Nota
O parâmetro limit_mm_per_prompt funciona apenas quando se utiliza o backend VLLM. Se o seu modelo utilizar outro backend, este parâmetro será ignorado.
Você pode encontrar mais exemplos sobre as capacidades do vision no notebook de tutorial.
Aprenda a usar as capacidades visuais de LLM através de exemplos com qwen-vl-chat.
áudio#
Através da funcionalidade de “áudio”, seu modelo pode receber áudio e realizar análise de áudio ou gerar respostas de texto diretamente com base em instruções de voz. No Xinference, isso significa que alguns modelos são capazes de processar entrada de áudio durante conversas por meio da Chat API.
Lista de modelos suportados#
O recurso “Áudio” no Xinference suporta os seguintes modelos:
Início Rápido#
O áudio pode ser fornecido ao modelo de duas maneiras principais: através do envio de um link de imagem ou passando diretamente uma URL de áudio na solicitação.
Conversa com áudio#
from xinference.client import Client
client = Client("http://<XINFERENCE_HOST>:<XINFERENCE_PORT>")
model = client.get_model(<MODEL_UID>)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3",
},
{"type": "text", "text": "What's that sound?"},
],
},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{
"role": "user",
"content": [
{"type": "text", "text": "What can you do when you hear that?"},
],
},
{
"role": "assistant",
"content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property.",
},
{
"role": "user",
"content": [
{
"type": "audio",
"audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac",
},
{"type": "text", "text": "What does the person say?"},
],
},
]
print(model.chat(messages))