Mecanismo de inferência#
O Xinference possui diferentes mecanismos de inferência para diferentes modelos. Após o usuário selecionar um modelo, o Xinference escolhe automaticamente o mecanismo adequado.
llama.cpp#
O Xinference atualmente suporta o xllamacpp desenvolvido pela equipe do Xinference como backend do llama.cpp para execução. O llama.cpp é baseado na biblioteca de tensores ggml e oferece suporte à inferência de modelos da série LLaMA e suas variações.
Aviso
A partir do Xinference v1.5.0, o xllamacpp tornou-se a opção padrão para o llama.cpp, e o llama-cpp-python foi descontinuado; a partir do Xinference v1.6.0, o llama-cpp-python foi removido.
Consulte a definição da estrutura common_params em common.h do llama.cpp para configurar os parâmetros.
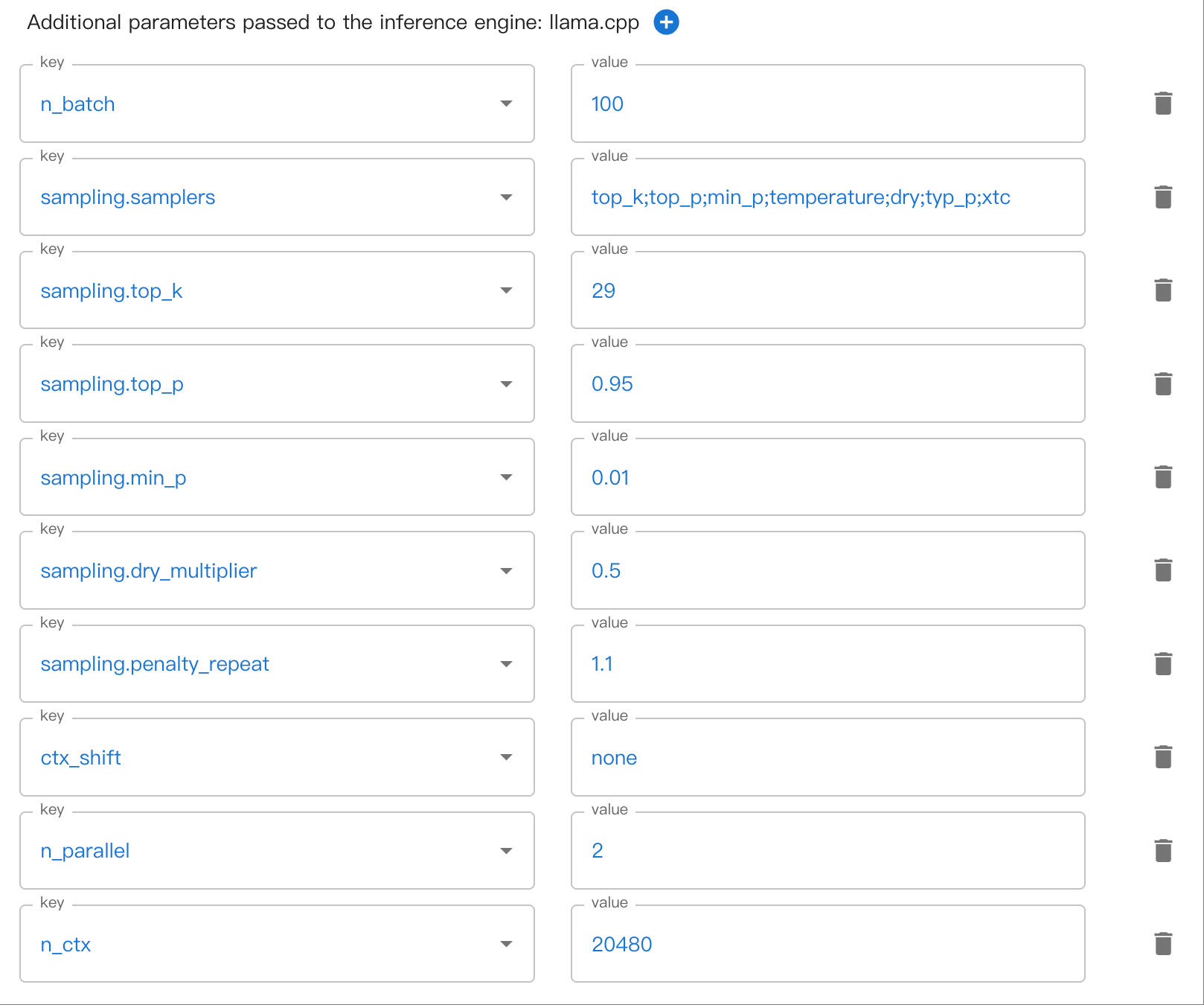
Pode haver parâmetros com múltiplos níveis de aninhamento. Por exemplo, sampling.top_k. Use . para separar parâmetros aninhados.
Aqui está um exemplo de configuração dos parâmetros de nested sampling na WebUI:
NGL automático#
Adicionado na versão v1.6.1: Desde v1.6.1, quando n-gpu-layers não é especificado (padrão -1), a estimativa do número de camadas da GPU é ativada automaticamente.
Este recurso pode definir automaticamente o número de camadas de GPU (NGL) para o backend llama.cpp. Observe que não é um cálculo preciso, portanto, o resultado de -ngl pode não ser ideal e ainda é possível encontrar erros de falta de memória de vídeo.
Atualmente, o NGL automático não tem suporte oficial. Consulte a issue abaixo para mais detalhes:
Nossa implementação é baseada no NGL automático do Ollama, mas com algumas diferenças:
Usamos as informações de dispositivo fornecidas pelo xllamacpp.
Removemos o suporte a algumas arquiteturas incomuns, nas quais a lógica de cálculo padrão era utilizada.
Se a NGL automática falhar, tentaremos carregar tudo na GPU.
Não oferecemos suporte para projetores multimodais incorporados ao GGUF do modelo. Esse formato de modelo ainda está em fase experimental.
Perguntas Frequentes#
Server error: {‘code’: 500, ‘message’: ‘failed to process image’, ‘type’: ‘server_error’}
Log do servidor:
encoding image or slice... slot update_slots: id 0 | task 0 | kv cache rm [10, end) srv process_chun: processing image... ggml_metal_graph_compute: command buffer 0 failed with status 5 error: Internal Error (0000000e:Internal Error) clip_image_batch_encode: ggml_backend_sched_graph_compute failed with error -1 failed to encode image srv process_chun: image processed in 2288 ms mtmd_helper_eval failed with status 1 slot update_slots: id 0 | task 0 | failed to process image, res = 1
Pode ser causado por memória insuficiente. Você pode tentar reduzir o
n_ctxpara resolver.Server error: {‘code’: 400, ‘message’: ‘the request exceeds the available context size. try increasing the context size or enable context shift’, ‘type’: ‘invalid_request_error’}
Se você estiver usando a funcionalidade multimodal, o
ctx_shiftserá desativado por padrão. Tente aumentar on_ctxou diminuir on_parallelpara aumentar o tamanho do contexto de cada slot.Server error: {‘code’: 500, ‘message’: ‘Input prompt is too big compared to KV size. Please try increasing KV size.’, ‘type’: ‘server_error’}
Log do servidor:
ggml_metal_graph_compute: command buffer 1 failed with status 5 error: Insufficient Memory (00000008:kIOGPUCommandBufferCallbackErrorOutOfMemory) graph_compute: ggml_backend_sched_graph_compute_async failed with error -1 llama_decode: failed to decode, ret = -3 srv update_slots: failed to decode the batch: KV cache is full - try increasing it via the context size, i = 0, n_batch = 2048, ret = -3
Isso pode ser causado por falha na criação do cache KV. Você pode resolver reduzindo o n_ctx, aumentando o n_parallel ou ajustando o parâmetro n_gpu_layers para carregar parte do modelo na GPU. Observe que, se você estiver lidando apenas com requisições de inferência serial, aumentar o n_parallel não trará ganhos de desempenho.
transformers#
O Transformers suporta a grande maioria dos modelos recém-lançados. É o motor padrão usado para modelos no formato Pytorch.
vLLM#
vLLM é um motor de inferência de modelo de linguagem grande muito eficiente e fácil de usar.
A vLLM tem as seguintes características:
Taxa de transferência de inferência líder
Uso de PagedAttention para gerenciar eficientemente a memória das chaves e valores de atenção
Loteamento contínuo de requisições recebidas
Kernel CUDA otimizado
Quando as seguintes condições forem atendidas, o Xinference selecionará automaticamente o vLLM como mecanismo de inferência:
O formato do modelo pode ser
pytorch,gptq,awq,fp4,fp8oubnb.Quando o formato do modelo for
pytorch, a opção de quantização deve sernone.Quando o formato do modelo for
awq, a opção de quantização deve serInt4.Quando o formato do modelo for
gptq, as opções de quantização devem serInt3,Int4ouInt8.O sistema operacional é Linux e há pelo menos um dispositivo compatível com CUDA.
Os campos
model_familydo modelo personalizado emodel_namedo modelo embutido estão na lista de suporte do vLLM.
Atualmente, os modelos suportados incluem:
code-llama,code-llama-instruct,code-llama-python,deepseek,deepseek-chat,deepseek-coder,deepseek-coder-instruct,deepseek-r1-distill-llama,gorilla-openfunctions-v2,HuatuoGPT-o1-LLaMA-3.1,llama-2,llama-2-chat,llama-3,llama-3-instruct,llama-3.1,llama-3.1-instruct,llama-3.3-instruct,minicpm5-1b,tiny-llama,wizardcoder-python-v1.0,wizardmath-v1.0,Yi,Yi-1.5,Yi-1.5-chat,Yi-1.5-chat-16k,Yi-200k,Yi-chatcodestral-v0.1,mistral-instruct-v0.1,mistral-instruct-v0.2,mistral-instruct-v0.3,mistral-large-instruct,mistral-nemo-instruct,mistral-v0.1,openhermes-2.5,seallm_v2Baichuan-M2,codeqwen1.5,codeqwen1.5-chat,deepseek-r1-distill-qwen,DianJin-R1,fin-r1,HuatuoGPT-o1-Qwen2.5,KAT-V1,marco-o1,qwen1.5-chat,qwen2-instruct,qwen2.5,qwen2.5-coder,qwen2.5-coder-instruct,qwen2.5-instruct,qwen2.5-instruct-1m,qwenLong-l1,QwQ-32B,QwQ-32B-Preview,seallms-v3,skywork-or1,skywork-or1-preview,XiYanSQL-QwenCoder-2504llama-3.2-vision,llama-3.2-vision-instructbaichuan-2,baichuan-2-chatInternLM2ForCausalLMqwen-chatmixtral-8x22B-instruct-v0.1,mixtral-instruct-v0.1,mixtral-v0.1cogagentglm-edge-chat,glm4-chat,glm4-chat-1mcodegeex4,glm-4vseallm_v2.5orion-chatqwen1.5-moe-chat,qwen2-moe-instructCohereForCausalLMdeepseek-v2-chat,deepseek-v2-chat-0628,deepseek-v2.5,deepseek-vl2deepseek-prover-v2,deepseek-r1,deepseek-r1-0528,deepseek-v3,deepseek-v3-0324,Deepseek-V3.1,moonlight-16b-a3b-instructdeepseek-r1-0528-qwen3,qwen3minicpm3-4binternlm3-instructgemma-3-1b-itglm4-0414minicpm-2b-dpo-bf16,minicpm-2b-dpo-fp16,minicpm-2b-dpo-fp32,minicpm-2b-sft-bf16,minicpm-2b-sft-fp32,minicpm4Ernie4.5Qwen3-Coder,Qwen3-Instruct,Qwen3-Thinkingglm-4.5,GLM-4.6,GLM-4.7gpt-ossseed-ossQwen3-Next-Instruct,Qwen3-Next-ThinkingDeepSeek-V3.2,DeepSeek-V3.2-ExpMiniMax-M2,MiniMax-M2.5,MiniMax-M2.7GLM-4.7-Flashglm-5,glm-5.1DeepSeek-V4-Flash,DeepSeek-V4-Pro
SGLang#
SGLang possui um runtime de inferência de alto desempenho baseado em RadixAttention. Ele acelera significativamente a execução de programas complexos de LLM ao reutilizar automaticamente o cache KV entre múltiplas chamadas. Também suporta outras técnicas comuns de inferência, como processamento em lote contínuo e paralelismo de tensor.
MLX#
MLX oferece uma maneira eficiente de executar LLMs em chips Apple Silicon. Quando o modelo está no formato MLX, recomenda-se que usuários de Mac com chips Apple Silicon utilizem o motor MLX.