Tradução para o português brasileiro:#
Alguns modelos de linguagem, incluindo DeepSeek V3, DeepSeek R1 e outros, são muito grandes para serem executados em GPUs de uma única máquina. O Xinference oferece suporte para executar esses modelos em várias máquinas.
Adicionado na versão v1.3.0.
Mecanismos compatíveis#
Agora, o Xinference suporta os seguintes motores para executar modelos em vários workers.
SGLang (suportado na v1.3.0)
vLLM (suportado na versão 1.4.1)
MLX (suportado desde v1.7.1) atualmente não oferece suporte a todos os modelos em modo distribuído. Atualmente, os seguintes tipos de modelo são suportados. Se você tiver outras necessidades, sinta-se à vontade para abrir uma issue no GitHub em xorbitsai/inference#issues para solicitar suporte.
DeepSeek v3 e R1
Qwen2.5-instruct e outros modelos com a mesma arquitetura de modelo.
Qwen3 e outros modelos com a mesma arquitetura de modelo.
Qwen3-moe e outros modelos com a mesma arquitetura de modelo.
Use#
Primeiro, você precisa de pelo menos 2 nós de trabalho para suportar inferência distribuída. Consulte Executando Xinference em um cluster para criar um cluster Xinference contendo um nó supervisor e nós de trabalho.
vLLM (v0.11.0+) Nota: A partir da versão vLLM v0.11.0, a implantação distribuída com vLLM requer a versão Xinference >= v1.17.1. Além da configuração original do parâmetro --n-worker, ao iniciar o modelo, também é necessário definir os parâmetros tensor_parallel_size (definido como número de GPUs) e pipeline_parallel_size=1.
Em seguida, se você estiver usando a interface Web, selecione o número desejado de máquinas como worker count na configuração opcional; se estiver usando a linha de comando, adicione --n-worker <número de máquinas> ao iniciar o modelo. O modelo será iniciado em vários nós de trabalho de acordo.
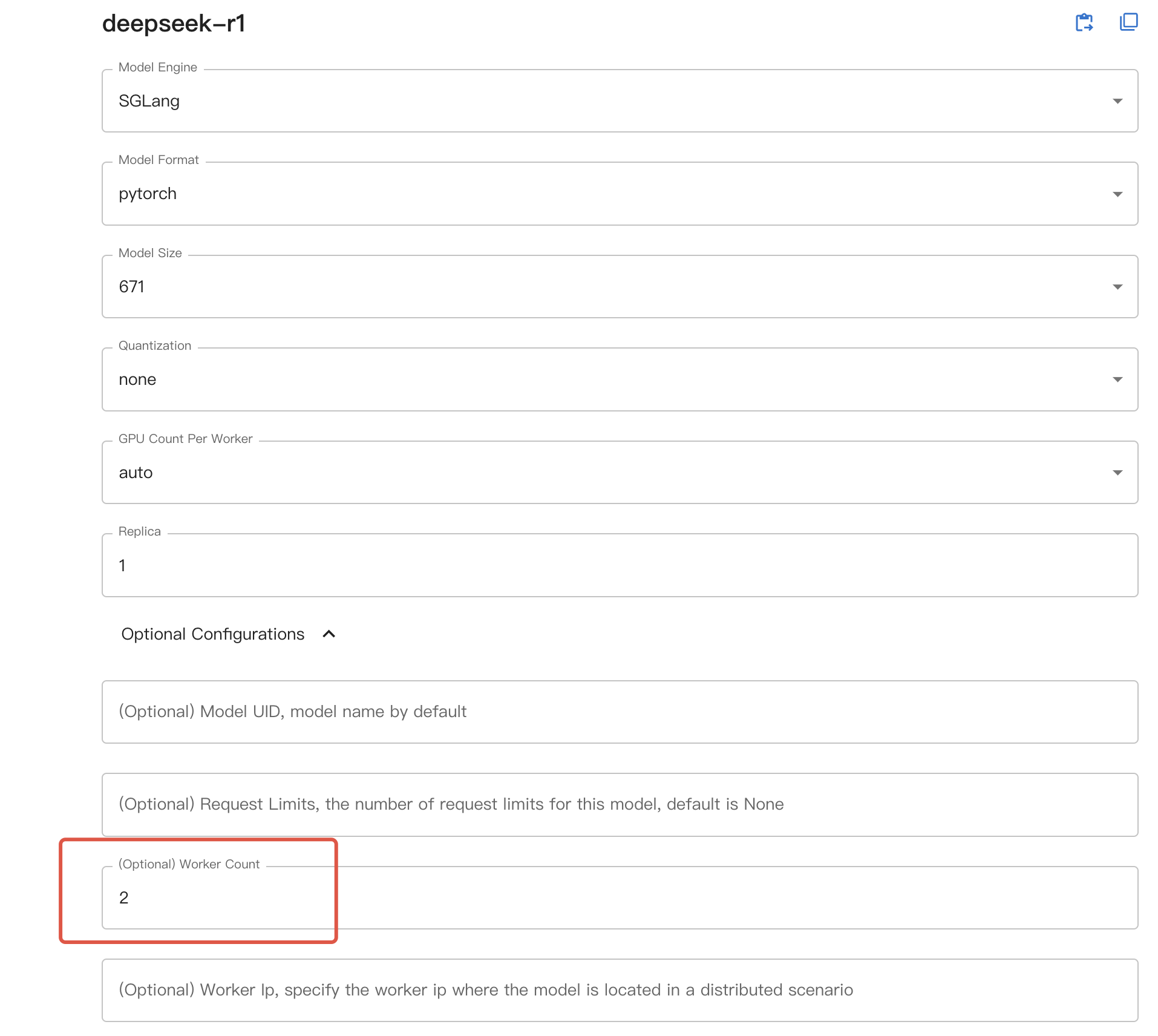
Ao usar inferência distribuída, o GPU count na interface web ou o --n-gpu na linha de comando agora representa o número de GPUs por nó de trabalho.